Moore数据集与可计算存储 数据压缩、数据库计算下推及数据处理存储支持服务的融合创新
随着数据量的爆炸式增长和数据处理需求的日益复杂,传统以CPU为中心的计算架构正面临瓶颈。以Moore数据集为代表的海量数据应用场景,正驱动着存储与计算融合的范式变革。可计算存储、数据压缩、数据库计算下推以及一体化的数据处理与存储支持服务,构成了应对这一挑战的关键技术体系,旨在提升效率、降低延迟与总拥有成本。
一、 Moore数据集:海量数据处理的新挑战
“Moore数据集”在此语境下,可理解为遵循摩尔定律般快速增长、规模庞大且需高效处理的数据集合。其特点包括:
- 体积巨大:数据量持续指数级增长。
- 价值密度低:需处理大量数据以提取有限洞察。
- 实时性要求高:许多应用需要低延迟的分析与响应。
- 存储与计算成本压力:数据移动和集中处理成本高昂。
这些挑战促使计算能力向数据所在地迁移,而非相反,从而催生了可计算存储等近数据计算技术。
二、 核心技术支柱:从压缩到下推
1. 数据压缩:存储效率的基石
在存储层进行高效压缩是管理Moore数据集的先决条件。现代技术不仅追求高压缩比,更强调:
- 查询感知压缩:采用允许直接在压缩数据上执行谓词筛选等操作的编码格式(如字典编码、RLE),避免完全解压的开销。
- 智能分层压缩:依据数据的热度、类型选择不同算法(如Zstd、Snappy用于热数据,高压缩比算法用于冷数据),平衡性能与空间。
- 硬件加速压缩:利用存储设备内置的专用硬件(如FPGA、ASIC)透明执行压缩/解压,释放主机CPU资源。
2. 数据库计算下推:将工作负载移至存储
计算下推是核心优化策略,指将部分数据库操作(如选择、投影、聚合、谓词筛选)下推到存储系统执行。其优势在于:
- 减少数据移动:仅将过滤后的有效结果或中间结果传回主机,极大降低I/O带宽消耗。
- 并行处理能力:利用存储设备内部的多核处理器或可编程单元,并行处理本地数据。
- 降低主机负载:主机CPU得以专注于更复杂的计算任务。
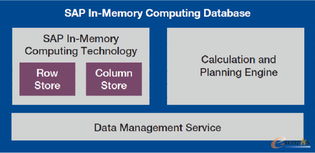
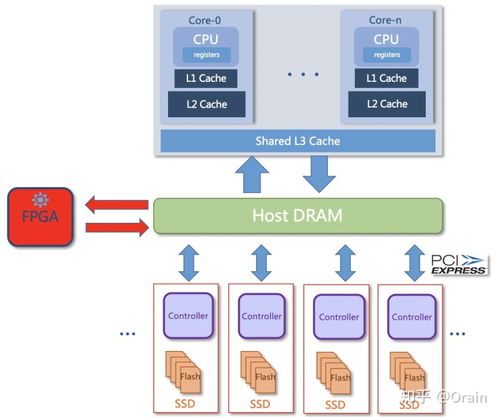
3. 可计算存储:硬件级的融合
可计算存储设备是上述理念的硬件载体。它通过在SSD、智能网卡或专用设备中集成可编程计算单元(如ARM核、FPGA),使存储设备具备原生数据处理能力。对于Moore数据集:
- 近数据计算:在数据存储的物理位置执行计算,彻底避免大规模数据迁移。
- 定制化加速:可为特定操作(如扫描、过滤、加密、转码)设计硬件加速流水线。
- 异构计算生态:与CPU、GPU协同,构成更均衡的异构计算架构。
三、 一体化数据处理与存储支持服务
技术最终需通过服务化的方式交付,以简化应用。一体化的支持服务通常包括:
- 智能数据编排:自动将数据与计算任务调度到最合适的层(热数据+高计算下推,冷数据+高压缩)。
- 统一API与SDK:为开发者提供简洁的接口,调用存储内的计算功能,而无需关心底层硬件细节。
- 可观测性与管理:提供监控、诊断工具,洞察计算下推的执行效率、压缩率、设备健康状况等。
- 安全与隔离:确保在存储设备内执行的计算任务具备足够的安全隔离和完整性保护。
四、 应用场景与未来展望
该技术组合在以下场景潜力巨大:
- 大规模分析型数据库:加速数据仓库、OLAP查询。
- 实时流处理与边缘计算:在数据产生源头进行即时过滤与聚合。
- AI/ML训练与推理:在存储层直接进行数据预处理、特征提取。
- 高性能计算:加速科学计算中大型数据集的分析。
未来趋势将聚焦于:更强大的标准化可计算存储接口(如CSI计算侧car)、更智能的自动化数据放置与计算调度、以及存储内计算与新兴计算范式(如存算一体)的进一步融合。
###
面对Moore数据集带来的严峻挑战,单纯提升存储容量或CPU性能已难以为继。通过深度融合数据压缩、数据库计算下推、可计算存储硬件,并构建强大的数据处理与存储支持服务,我们能够构建一个更高效、更经济、更敏捷的数据基础设施。这不仅是技术的演进,更是从“数据移动计算”到“计算贴近数据”的根本性理念转变,为大数据与人工智能时代奠定新的基石。
如若转载,请注明出处:http://www.51xmlong.com/product/74.html
更新时间:2026-06-19 17:35:54