MaxCompute 湖仓一体近实时增量处理技术架构揭秘
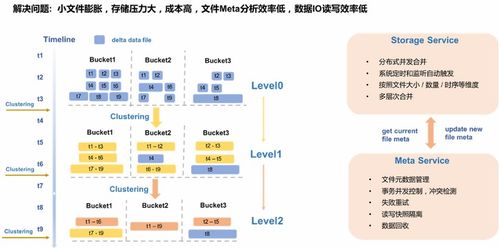
随着数据量的爆炸式增长和数据应用场景的多样化,传统的数据仓库和数据湖架构在实时性、灵活性和成本效益方面逐渐显现不足。阿里云 MaxCompute 作为业界领先的大数据计算平台,推出了湖仓一体架构,结合近实时增量处理技术,有效解决了大规模数据处理中的实时性和存储效率问题。本文将深入解析 MaxCompute 湖仓一体的近实时增量处理技术架构,并探讨其在数据处理和存储支持服务方面的优势。
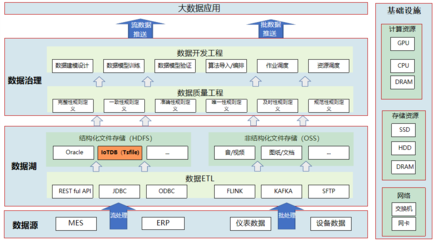
一、湖仓一体架构概述
湖仓一体架构是数据湖与数据仓库的融合体,旨在兼具数据湖的灵活性和数据仓库的高性能。MaxCompute 湖仓一体架构通过统一的数据管理和计算引擎,实现了对结构化与非结构化数据的统一存储和处理。其核心在于通过分层存储(如 OSS 对象存储与 MaxCompute 内部存储)和智能元数据管理,支持数据的无缝流动和统一访问。
二、近实时增量处理技术
近实时增量处理是 MaxCompute 湖仓一体架构的关键组成部分,它能够以分钟级延迟处理数据变更,适用于实时分析和业务监控场景。该技术基于以下机制:
- 增量数据捕获:通过 CDC(Change Data Capture)工具或日志解析技术(如 Canal 或 Flink CDC),实时捕获源数据库的变更事件。
- 数据流处理:利用 MaxCompute 的流计算能力(如 Realtime Compute 或 Flink 集成),对增量数据进行清洗、转换和聚合,确保数据质量和一致性。
- 增量合并与更新:通过 upsert 操作或事务性表(如 Hudi 或 Iceberg 集成),将增量数据高效合并到目标表中,避免全量重刷带来的资源浪费。
这一技术显著提升了数据处理的时效性,同时降低了计算和存储成本,支持用户快速响应业务变化。
三、数据处理支持服务
MaxCompute 湖仓一体架构提供了全面的数据处理支持服务,确保数据从采集到消费的高效流转:
- 多源数据集成:支持从关系型数据库、日志文件、消息队列(如 Kafka)等多种数据源实时接入,通过 DataWorks 等工具实现数据同步和调度。
- 弹性计算能力:基于 Serverless 架构,MaxCompute 可根据负载自动扩缩容,并行处理大规模数据,并提供 SQL、Python 和 Spark 等多种计算引擎,满足不同开发需求。
- 数据质量与治理:内置数据质量监控、血缘分析和权限管理功能,确保数据在增量处理过程中的准确性、安全性和可追溯性。
四、存储支持服务
在存储方面,MaxCompute 湖仓一体架构结合了数据湖的廉价存储和数据仓库的高性能查询优势:
- 分层存储设计:热数据存储在 MaxCompute 内部高性能存储中,冷数据自动迁移至 OSS 对象存储,通过智能生命周期管理优化成本。
- 开放数据格式:支持 Parquet、ORC 等列式存储格式,并与开源表格式(如 Hudi 和 Iceberg)兼容,便于数据共享和跨平台分析。
- 元数据统一管理:通过 MaxCompute 元数据服务,实现表、分区和数据的统一视图,支持跨数据源的联合查询和数据发现。
五、应用场景与优势
MaxCompute 湖仓一体的近实时增量处理技术已在电商实时推荐、金融风控、物联网监控等场景中广泛应用。其优势包括:
- 低延迟高时效:分钟级数据处理能力,满足业务对实时性的需求。
- 成本效益:通过增量处理和分层存储,大幅降低存储和计算开销。
- 灵活扩展:支持 PB 级数据规模,并具备高可用和容灾能力。
- 生态集成:与阿里云生态(如 DataWorks、Flink)无缝集成,简化数据流水线构建。
六、总结
MaxCompute 湖仓一体近实时增量处理技术架构通过融合数据湖与数据仓库的优势,结合高效的增量处理机制,为现代企业提供了强大、灵活的数据处理与存储解决方案。随着数据驱动决策的普及,这一架构将持续演进,助力用户实现数据价值的最大化。未来,MaxCompute 将进一步优化实时能力,并深化与 AI 和机器学习的集成,推动数据智能的全面发展。
如若转载,请注明出处:http://www.51xmlong.com/product/16.html
更新时间:2025-11-29 02:31:24