Apache Ozone 面向密集型数据节点的数据处理与存储支持服务解析
在当今大数据与云原生时代,海量数据的存储与高效处理成为企业面临的核心挑战。Apache Ozone,作为一个分布式、可扩展的对象存储系统,专为处理密集型数据节点场景而设计,为现代数据架构提供了强大的数据处理与存储支持服务。
一、Apache Ozone 的核心架构与定位
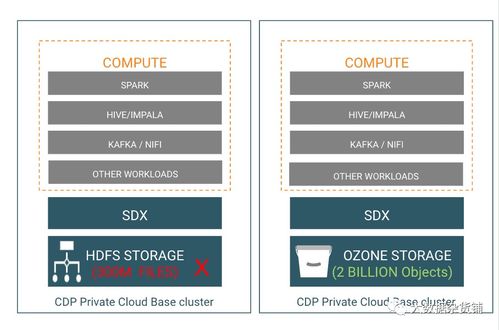
Apache Ozone 是 Apache Hadoop 生态系统中的新一代存储系统,它采用对象存储模型,支持海量小文件和大对象的统一存储。其架构设计天然适合密集型数据节点部署,通过将存储元数据与数据分离,并引入多层命名空间(卷、桶、键)管理,Ozone 能够轻松应对高并发访问和海量数据扩展的需求。
二、密集型数据节点的数据处理支持
在密集型数据节点环境中,数据往往以极高的速率产生和流动。Apache Ozone 通过以下机制提供强大的数据处理支持:
- 高吞吐量与低延迟:Ozone 支持多协议访问(如 O3FS、S3A),可与 Hadoop、Spark、Flink 等计算框架无缝集成,确保数据读写的高效性。
- 数据本地化优化:通过智能的数据放置策略,Ozone 尽可能将计算任务调度到存储节点附近,减少网络传输开销,提升数据处理性能。
- 弹性扩展能力:Ozone 的存储池(Storage Pool)模型允许动态添加或移除数据节点,无需中断服务,非常适合需要频繁调整规模的密集型数据处理场景。
三、密集型数据节点的存储支持服务
对于存储密集型工作负载,Ozone 提供了多层次的服务保障:
- 高可靠性与持久性:采用多副本或纠删码(Erasure Coding)机制,确保数据在节点故障时不会丢失。其强一致性的元数据管理(通过 Apache Ratis 实现)进一步保障了数据完整性。
- 存储分层与成本优化:Ozone 支持与云存储或冷存储介质集成,可实现数据的自动分层存储,在保证热数据高性能访问的降低整体存储成本。
- 多租户与配额管理:通过卷(Volume)和桶(Bucket)级别的隔离与配额控制,Ozone 能够安全、高效地服务于多个团队或应用,避免资源争用。
四、应用场景与最佳实践
Apache Ozone 特别适用于以下密集型数据节点场景:
- 大规模数据湖存储:作为统一的数据湖存储层,承接来自物联网、日志、交易系统等的高频数据注入。
- 云原生分析与机器学习:在 Kubernetes 环境中,Ozone 可作为持久化存储卷,支持弹性伸缩的批处理与流式计算任务。
- 备份与归档系统:凭借其高可靠性和扩展性,成为企业级备份与长期数据归档的理想选择。
最佳实践建议包括:合理规划存储池规模、根据数据热度配置存储策略、监控节点负载并实现自动化运维。
五、未来展望
随着数据密集型应用的不断演进,Apache Ozone 社区正持续优化其性能、安全性与生态系统集成。例如,增强对非结构化数据的智能索引支持、深化与云原生监控工具的融合等,都将进一步巩固其在密集型数据存储与处理领域的核心地位。
Apache Ozone 通过其现代化的架构设计与丰富的功能集,为密集型数据节点提供了坚实的数据处理与存储支持服务,是企业构建高效、可靠、可扩展数据平台的重要技术选择。
如若转载,请注明出处:http://www.51xmlong.com/product/69.html
更新时间:2026-06-19 09:15:15